クラウドPBX・コールセンターシステムの
Omnia LINK(オムニアリンク)

クラウドPBX・コールセンターシステムの
Omnia LINK(オムニアリンク)
クラウドPBX・コールセンターシステムの
Omnia LINK(オムニアリンク)
学べるコラム

今さら聞けない!? 初歩の初歩
AI音声認識の仕組みを徹底解説!メリットや課題、活用事例もご紹介
2023年7月13日

昨今、社会の幅広い分野で、「AI音声認識」が急速に浸透しています。AI音声認識技術が組み込まれていることを意識しないまま、日常生活の中で触れている方もいらっしゃるかもしれません。なお、株式会社グローバルインフォメーションの調査によると、音声認識・言語認識技術関連サービスの市場規模は、2022年の94億米ドルから、2027年には281億米ドルにまで到達すると予想されています。
AI音声認識は、スマートフォンやスマートスピーカー、議事録・報告書・カルテの作成、外国人観光客との意思疎通、コールセンター業務など、多種多様な製品・シーンで使われている技術ですが、「仕組みがよく分からない」とお悩みの方がいらっしゃるかもしれません。
とはいえ、「理解できないから、導入しない」という姿勢では、世の中の流れから取り残されてしまいます。今後さらなる需要の高まりや、ソフトウェア/ハードウェアの進歩などにより、今後、さらにAI音声認識技術に振れる場面が増加していく見込みです。また、コールセンターにおいてもAI音声認識技術が大いに活用されているので、この機会にしっかりと内容を理解しておきましょう。
本記事では、主にコールセンターの開設を検討している企業や、すでに運営を開始している企業の担当者に向けて、AI音声認識の仕組みについて詳しく解説します。メリットや、課題・注意点、活用事例、高精度な音声認識システムが標準搭載されているコールセンターシステムもご紹介するので、ぜひ参考にしてください。
>>リアルタイム音声認識でモニタリング体制を構築!応対品質を向上した事例はこちら
AI音声認識は、スマートフォンやスマートスピーカー、議事録・報告書・カルテの作成、外国人観光客との意思疎通、コールセンター業務など、多種多様な製品・シーンで使われている技術ですが、「仕組みがよく分からない」とお悩みの方がいらっしゃるかもしれません。
とはいえ、「理解できないから、導入しない」という姿勢では、世の中の流れから取り残されてしまいます。今後さらなる需要の高まりや、ソフトウェア/ハードウェアの進歩などにより、今後、さらにAI音声認識技術に振れる場面が増加していく見込みです。また、コールセンターにおいてもAI音声認識技術が大いに活用されているので、この機会にしっかりと内容を理解しておきましょう。
本記事では、主にコールセンターの開設を検討している企業や、すでに運営を開始している企業の担当者に向けて、AI音声認識の仕組みについて詳しく解説します。メリットや、課題・注意点、活用事例、高精度な音声認識システムが標準搭載されているコールセンターシステムもご紹介するので、ぜひ参考にしてください。
>>リアルタイム音声認識でモニタリング体制を構築!応対品質を向上した事例はこちら
AI音声認識とは?
「音声認識」とは、会話を録音した音声データを解析し、文字データ(テキスト)に変換する技術です。そして、「AI(人工知能)」を活用した音声認識技術を「AI音声認識」と呼ぶことを覚えておきましょう。
なお、AI(Artificial Intelligence)とは、「人間の思考プロセスと同じように動作するプログラム・技術」であり、音声認識だけではなく、画像認識や自動運転など、多種多様な分野で活用されています。ちなみに、AIは「強いAI」と「弱いAI」に大別されますが、現時点で実現されているのは後者のみです。
強いAI(汎用型AI)とは、「人間と同じように自我を持って、自律的に思考するAI」を指し、フィクション(映画や漫画、アニメ、ゲーム)内では多数登場しているものの、現実世界において実現されるのは、まだ先の時代になるでしょう。それに対し、弱いAI(特化型AI)とは「特定の分野・領域に特化したAI」を指し、音声認識技術で利用されるAIは「弱いAI」に分類されます。
音声認識技術の開発の歴史は、1950年代にスタートしました。しばらくの間、特筆するべき商品・サービスは誕生しませんでしたが、1970年代になるとアメリカのDARPA(国防高等研究計画局)などで本格的に研究が進められるようになります。その後、人間の音声を「数式」で表現することが可能になりました。
1990年代~2000年代には、アルゴリズムの改善によって認識精度が向上したことで、音声認識機能が搭載されたカーナビゲーションシステムやパソコン用アプリケーションソフト、ゲームなどが普及するようになります。
状況を大きく変えたのは、2010年代における「ディープラーニング(深層学習)技術」の発展です。「ニューラルネットワーク」(人間の脳神経回路からヒントを得た数理モデル・情報処理方法)によって、パターン認識の精度が向上しました。
2023年時点において、AI音声認識技術を活用することは、企業の経済活動にとって不可欠といえるでしょう。日常生活にも浸透しており、身近な例では、スマートフォンのAI音声認識機能が挙げられます(Androidの「Googleアシスタント」、iPhoneの「Siri」など)。これら以外にも、多種多様なシーンでAI音声認識技術が活用される時代が到来しています。
なお、AI(Artificial Intelligence)とは、「人間の思考プロセスと同じように動作するプログラム・技術」であり、音声認識だけではなく、画像認識や自動運転など、多種多様な分野で活用されています。ちなみに、AIは「強いAI」と「弱いAI」に大別されますが、現時点で実現されているのは後者のみです。
強いAI(汎用型AI)とは、「人間と同じように自我を持って、自律的に思考するAI」を指し、フィクション(映画や漫画、アニメ、ゲーム)内では多数登場しているものの、現実世界において実現されるのは、まだ先の時代になるでしょう。それに対し、弱いAI(特化型AI)とは「特定の分野・領域に特化したAI」を指し、音声認識技術で利用されるAIは「弱いAI」に分類されます。
音声認識技術の開発の歴史は、1950年代にスタートしました。しばらくの間、特筆するべき商品・サービスは誕生しませんでしたが、1970年代になるとアメリカのDARPA(国防高等研究計画局)などで本格的に研究が進められるようになります。その後、人間の音声を「数式」で表現することが可能になりました。
1990年代~2000年代には、アルゴリズムの改善によって認識精度が向上したことで、音声認識機能が搭載されたカーナビゲーションシステムやパソコン用アプリケーションソフト、ゲームなどが普及するようになります。
状況を大きく変えたのは、2010年代における「ディープラーニング(深層学習)技術」の発展です。「ニューラルネットワーク」(人間の脳神経回路からヒントを得た数理モデル・情報処理方法)によって、パターン認識の精度が向上しました。
2023年時点において、AI音声認識技術を活用することは、企業の経済活動にとって不可欠といえるでしょう。日常生活にも浸透しており、身近な例では、スマートフォンのAI音声認識機能が挙げられます(Androidの「Googleアシスタント」、iPhoneの「Siri」など)。これら以外にも、多種多様なシーンでAI音声認識技術が活用される時代が到来しています。
音声認識の仕組み

ここからは、「従来型の音声認識」、および、ディープラーニング技術の発展によって飛躍的に精度が向上した「近年のAI音声認識」の仕組みについて、順番に説明していきます。
なお、「音声」とは、人間の調音器官(舌、唇、歯、声帯など)を複雑に使用して発せられるものです。人間は自然に声を発し、耳で聴き取り、脳で意味を理解することが可能ですが、機械(コンピューター、ソフトウェア)にとっては容易なことではありません。
日本語の場合、典型的には、母音は「あ(a)」「い(i)」「う(u)」「え(e)」「お(o)」の5種類、子音は14種類とされています。しかし細かく見ていくと、より多くの種類が存在し、話者によっては典型的な音素以外で発音しているケースもあります。
また、性別、年齢などによって音の高さ(周波数)が異なり、話者ごとの癖(言葉遣いの差)もあります。もちろん、人間の声と、それ以外の音(虫や鳥の鳴き声、風の音、機械の作動音など)を区別することも不可欠です。
次節以降でご紹介する方法によって、このような多種多様な音素が含まれる音声データが解析され、文章化されています。
多くの従来型音声認識システムは、「音響モデル」「発音辞書」「言語モデル」という3つのモジュールを組み合わせて実現されています。以下は、「音声データの入力」から、「音響モデル、発音辞書、言語モデルによる解析」を経て、「文字データの出力」に至るまでの具体的な流れです。
1. マイクなどの入力デバイスで、人間の音声データを入力・録音する
2. 入力された音声から「周波数」「強弱」「音と音の間隔」といった特徴を取り出し、コンピューターが認識しやすいデータに加工する
3. 「音響モデル」によって音素を特定する(統計的に処理したデータと照合し、最も近い音素を見つけ出す)
4. 「発音辞書」や「言語モデル」を用いて、パターンマッチを実行する(音素を意味のある単語に変換し、文章化する)
5. テキストデータとして出力・保存する
なお、3の段階において、例えば、「自宅の近く」というフレーズの音声データ場合は、「jitakunochikaku」という音素列が抽出されます。
そして、4の段階において、発音辞書によって「jitaku」に対して「自宅」が、「no」に対して「の」または「野」が、「chikaku」に対して「近く」「地殻」「地核」「知覚」といった候補が割り当てられていきます。
その後、「数多くの日本語文章を統計的に処理した言語モデル」(隠れマルコフモデル、Hidden Markov Model)によって「出現確率が高い組み合わせ」で文章化、つまり「自宅の地殻」や「自宅の地核」「自宅の知覚」ではなく、最も出現確率が高い「自宅の近く」に変換されることになります。
近年、ディープラーニング技術が大きく発展したことにより、AI音声認識が幅広く用いられる時代になりました。ディープラーニングとは、人間が特徴を教え込まなくても、大量のデータからAIが自律的にパターンを学習する技術であり、「深層学習」とも呼ばれます。
なお、「人間の脳内での処理と同じように、入力してから出力するまで、ダイレクトに音声を認識するモデル」(End-to-Endモデル)の採用によって、音声認識の精度が飛躍的に向上しました。
最新のAI音声認識システムは、従来型音声認識システムのように「音響モデル」「発音辞書」「言語モデル」という3つのモジュールを用いるのではなく、「ひとつのニューラルネットワーク」で実現されています。
なお、「音声」とは、人間の調音器官(舌、唇、歯、声帯など)を複雑に使用して発せられるものです。人間は自然に声を発し、耳で聴き取り、脳で意味を理解することが可能ですが、機械(コンピューター、ソフトウェア)にとっては容易なことではありません。
日本語の場合、典型的には、母音は「あ(a)」「い(i)」「う(u)」「え(e)」「お(o)」の5種類、子音は14種類とされています。しかし細かく見ていくと、より多くの種類が存在し、話者によっては典型的な音素以外で発音しているケースもあります。
また、性別、年齢などによって音の高さ(周波数)が異なり、話者ごとの癖(言葉遣いの差)もあります。もちろん、人間の声と、それ以外の音(虫や鳥の鳴き声、風の音、機械の作動音など)を区別することも不可欠です。
次節以降でご紹介する方法によって、このような多種多様な音素が含まれる音声データが解析され、文章化されています。
従来型の音声認識の仕組み
多くの従来型音声認識システムは、「音響モデル」「発音辞書」「言語モデル」という3つのモジュールを組み合わせて実現されています。以下は、「音声データの入力」から、「音響モデル、発音辞書、言語モデルによる解析」を経て、「文字データの出力」に至るまでの具体的な流れです。
1. マイクなどの入力デバイスで、人間の音声データを入力・録音する
2. 入力された音声から「周波数」「強弱」「音と音の間隔」といった特徴を取り出し、コンピューターが認識しやすいデータに加工する
3. 「音響モデル」によって音素を特定する(統計的に処理したデータと照合し、最も近い音素を見つけ出す)
4. 「発音辞書」や「言語モデル」を用いて、パターンマッチを実行する(音素を意味のある単語に変換し、文章化する)
5. テキストデータとして出力・保存する
なお、3の段階において、例えば、「自宅の近く」というフレーズの音声データ場合は、「jitakunochikaku」という音素列が抽出されます。
そして、4の段階において、発音辞書によって「jitaku」に対して「自宅」が、「no」に対して「の」または「野」が、「chikaku」に対して「近く」「地殻」「地核」「知覚」といった候補が割り当てられていきます。
その後、「数多くの日本語文章を統計的に処理した言語モデル」(隠れマルコフモデル、Hidden Markov Model)によって「出現確率が高い組み合わせ」で文章化、つまり「自宅の地殻」や「自宅の地核」「自宅の知覚」ではなく、最も出現確率が高い「自宅の近く」に変換されることになります。
近年のAI音声認識の仕組み
近年、ディープラーニング技術が大きく発展したことにより、AI音声認識が幅広く用いられる時代になりました。ディープラーニングとは、人間が特徴を教え込まなくても、大量のデータからAIが自律的にパターンを学習する技術であり、「深層学習」とも呼ばれます。
なお、「人間の脳内での処理と同じように、入力してから出力するまで、ダイレクトに音声を認識するモデル」(End-to-Endモデル)の採用によって、音声認識の精度が飛躍的に向上しました。
最新のAI音声認識システムは、従来型音声認識システムのように「音響モデル」「発音辞書」「言語モデル」という3つのモジュールを用いるのではなく、「ひとつのニューラルネットワーク」で実現されています。
AI音声認識のメリット
以下は、AI音声認識を導入することで享受できる主なメリットです。
• 業務が効率化される
• ユーザビリティが向上する
• 問い合わせ窓口の応答を自動化できる
それぞれについて詳しく説明します。
「会議」「打ち合わせ」などを行う際に、ICレコーダーで会話内容を録音していても、それを最初から最後まで聞いて書き起こすのは、多大な時間・労力がかかります。例えば、1時間の会議であれば、文字起こしに1時間以上の時間が必要です。
AI音声認識を導入すれば、自動的に音声データを解析し、漢字変換も行ってテキストデータの形で出力・保存してくれるため、人間が手作業で記録を作成する必要がなくなります。業務が効率化され、生産性が向上することに加えて、残業時間が少なくなり、労働環境の改善にも役立つでしょう。
日本は、少子高齢化に伴う生産年齢人口の減少により、深刻な人手不足に直面しています。このような状況において、優秀な人材を確保するためには、「働きやすい職場環境を構築すること」が不可欠です。
AI音声認識システムを導入して業務を効率化すれば、従業員に過度の負担がかかることを回避できます。よりコアな業務に集中できるのはもちろん、ワーク・ライフ・バランスが改善され、新規に人材を採用しやすくなるでしょう。また、すでに働いている従業員の定着率の向上(離職率の低下)にもつながります。
キーボードで文字などを入力する作業は、不慣れな人の場合、ミスをしたり、時間がかかったりするものです。ボタン操作であっても、多数のボタンが設置されている機器・ソフトウェアの場合、「どのボタンを、どの順番で押せば良いのか分からない」という状況に陥る可能性があります。
音声認識AIが搭載されているツールやシステムなら、操作が簡単です。人間と会話する感覚で、「口頭での指示」を出すだけで作動するので、工場内で手が濡れていたり、汚れていたりする場合や、機械操作・運転をしていて手が離せない状況でも指示を出すことが可能です。
問い合わせ窓口の応答を自動化できる
問い合わせ窓口の応答の一部を自動化できることも、AI音声認識を導入するメリットです。顧客が電話をかけてきたら、まず「お問い合わせの内容を30秒以内で簡単にお話しください」といった自動音声メッセージを流し、質問・相談内容を話してもらいましょう。
AI音声認識システムが内容を分析し、例えば、「今月の料金はいくらですか?」という質問に対して、自動的に「今月の請求金額は、税込みで7,500円です」のように回答することで、人件費(オペレーターの人員)を削減することが可能になります。
ただし、「人間が完全に不要になる」というわけではありません。後述するように、AIには「微妙なニュアンスを把握できない」という課題があります。AIによる回答が難しい場合や、顧客が希望する場合は、オペレーターに転送する必要があります。
• 業務が効率化される
• ユーザビリティが向上する
• 問い合わせ窓口の応答を自動化できる
それぞれについて詳しく説明します。
業務が効率化される
「会議」「打ち合わせ」などを行う際に、ICレコーダーで会話内容を録音していても、それを最初から最後まで聞いて書き起こすのは、多大な時間・労力がかかります。例えば、1時間の会議であれば、文字起こしに1時間以上の時間が必要です。
AI音声認識を導入すれば、自動的に音声データを解析し、漢字変換も行ってテキストデータの形で出力・保存してくれるため、人間が手作業で記録を作成する必要がなくなります。業務が効率化され、生産性が向上することに加えて、残業時間が少なくなり、労働環境の改善にも役立つでしょう。
日本は、少子高齢化に伴う生産年齢人口の減少により、深刻な人手不足に直面しています。このような状況において、優秀な人材を確保するためには、「働きやすい職場環境を構築すること」が不可欠です。
AI音声認識システムを導入して業務を効率化すれば、従業員に過度の負担がかかることを回避できます。よりコアな業務に集中できるのはもちろん、ワーク・ライフ・バランスが改善され、新規に人材を採用しやすくなるでしょう。また、すでに働いている従業員の定着率の向上(離職率の低下)にもつながります。
ユーザビリティが向上する
キーボードで文字などを入力する作業は、不慣れな人の場合、ミスをしたり、時間がかかったりするものです。ボタン操作であっても、多数のボタンが設置されている機器・ソフトウェアの場合、「どのボタンを、どの順番で押せば良いのか分からない」という状況に陥る可能性があります。
音声認識AIが搭載されているツールやシステムなら、操作が簡単です。人間と会話する感覚で、「口頭での指示」を出すだけで作動するので、工場内で手が濡れていたり、汚れていたりする場合や、機械操作・運転をしていて手が離せない状況でも指示を出すことが可能です。
問い合わせ窓口の応答を自動化できる
問い合わせ窓口の応答の一部を自動化できることも、AI音声認識を導入するメリットです。顧客が電話をかけてきたら、まず「お問い合わせの内容を30秒以内で簡単にお話しください」といった自動音声メッセージを流し、質問・相談内容を話してもらいましょう。
AI音声認識システムが内容を分析し、例えば、「今月の料金はいくらですか?」という質問に対して、自動的に「今月の請求金額は、税込みで7,500円です」のように回答することで、人件費(オペレーターの人員)を削減することが可能になります。
ただし、「人間が完全に不要になる」というわけではありません。後述するように、AIには「微妙なニュアンスを把握できない」という課題があります。AIによる回答が難しい場合や、顧客が希望する場合は、オペレーターに転送する必要があります。
AI音声認識の課題・注意点
AI音声認識には、メリットだけではなく、以下に示すような課題・注意点もあることを認識しておきましょう。
• 標準語以外の場合、精度が低下する
• 微妙なニュアンスを把握できない
• ノイズ(雑音)に弱い
それぞれについて詳しく説明します。
多くの音声認識システムは、「標準語」に基づいて作られています。そのため、「方言(訛り)」「若者言葉」「スラング」など、標準語以外を含む会話に関しては、学習データが少ないため、精度が低下します。また、特殊な業界用語や社内用語なども、正しく認識されない可能性があります。
なお、ツールによっては方言や専門用語に対応している場合もあるので、システムを導入する際に仕様をチェックし、自社に適したものをお選びください。
AIは、長足の進歩を遂げています。しかし現時点では、人間と同等のレベルで会話の内容を理解することはできません。微妙なニュアンスを汲み取ったり、意訳したりすることは苦手です。
例えば、親が子どもに対して「もう遅い時間だから、気を付けてね」と言い聞かせたとしましょう。人間であれば、「夜道は、暗くて周囲を見渡しにくくなるから、犯罪に巻き込まれないように注意しなければならない」というように理解することが可能です。しかしながら、AI音声認識は、「一般常識」「社会通念」「道徳」「倫理」などを踏まえた「微妙なニュアンス」を正しく把握できません。
音声認識ではなく、画像認識の領域になりますが、2015年に「Google Photos」に保存された画像データ(人物の写真)に対し、AIが自動的に「ゴリラ」というタグを付ける出来事が発生しました。人間がタグを付ける作業をしていれば、発生しなかったであろうトラブルです。
また、AI音声認識では、「私はうなぎ」というフレーズの意味も、適切に汲み取れない場合があります。もちろん、オフィスや学校で「私はうなぎ」と叫んだ場合、人間であっても意図を理解するのが困難です。しかし、食堂で「私はうなぎ」と言った場合は、「私は、うなぎを注文します」という意味であることが、人間には容易に理解できるでしょう。
そのため、「AIは万能なツールである」と捉えるのではなく、不完全な部分もあることを認識しておく必要があります。不足している部分を人間が補って、上手にAI音声認識システムを活用しましょう。
音声データにノイズ(雑音)が混入していると、認識精度が低下します。また、複数人が会話に参加している場合、特定の人の声だけを抽出することも苦手としています。
人間の場合、騒がしい場所(パーティー会場、繁華街など)であっても、「自分にとって関心のある話題」や「特定の人物の声」だけを選択的に聴き取ることが可能です。この効果・機能は、「カクテルパーティー効果」「選択的注意」「選択的聴取」などと呼ばれ、1953年にイギリスの心理学者コリン・チェリー(Edward Colin Cherry)よって提唱されました。
脳内での詳しいメカニズムは解明されていませんが、処理する情報量をコントロールするために、無意識のうちに、音声情報を取捨選択していると考えられています。ちなみに、聴覚だけではなく、視覚でも同様の「情報の取捨選択」が行われており、「カラーバス効果」と呼ばれています。
現時点においては、多くのAI音声認識技術では、人間の耳・脳と同レベルの精度で聴き分けることが困難です。そのため、AI音声認識を利用する際は、「雑音がない場所(静かな環境)で話す」「複数人で同時に会話しない(1人ずつ順番に話していく)」といった対策を講じましょう。ノイズを低減するソフトウェアや、高性能なマイクを使用することも重要です。
• 標準語以外の場合、精度が低下する
• 微妙なニュアンスを把握できない
• ノイズ(雑音)に弱い
それぞれについて詳しく説明します。
標準語以外の場合、精度が低下する
多くの音声認識システムは、「標準語」に基づいて作られています。そのため、「方言(訛り)」「若者言葉」「スラング」など、標準語以外を含む会話に関しては、学習データが少ないため、精度が低下します。また、特殊な業界用語や社内用語なども、正しく認識されない可能性があります。
なお、ツールによっては方言や専門用語に対応している場合もあるので、システムを導入する際に仕様をチェックし、自社に適したものをお選びください。
微妙なニュアンスを把握できない
AIは、長足の進歩を遂げています。しかし現時点では、人間と同等のレベルで会話の内容を理解することはできません。微妙なニュアンスを汲み取ったり、意訳したりすることは苦手です。
例えば、親が子どもに対して「もう遅い時間だから、気を付けてね」と言い聞かせたとしましょう。人間であれば、「夜道は、暗くて周囲を見渡しにくくなるから、犯罪に巻き込まれないように注意しなければならない」というように理解することが可能です。しかしながら、AI音声認識は、「一般常識」「社会通念」「道徳」「倫理」などを踏まえた「微妙なニュアンス」を正しく把握できません。
音声認識ではなく、画像認識の領域になりますが、2015年に「Google Photos」に保存された画像データ(人物の写真)に対し、AIが自動的に「ゴリラ」というタグを付ける出来事が発生しました。人間がタグを付ける作業をしていれば、発生しなかったであろうトラブルです。
また、AI音声認識では、「私はうなぎ」というフレーズの意味も、適切に汲み取れない場合があります。もちろん、オフィスや学校で「私はうなぎ」と叫んだ場合、人間であっても意図を理解するのが困難です。しかし、食堂で「私はうなぎ」と言った場合は、「私は、うなぎを注文します」という意味であることが、人間には容易に理解できるでしょう。
そのため、「AIは万能なツールである」と捉えるのではなく、不完全な部分もあることを認識しておく必要があります。不足している部分を人間が補って、上手にAI音声認識システムを活用しましょう。
ノイズ(雑音)に弱い
音声データにノイズ(雑音)が混入していると、認識精度が低下します。また、複数人が会話に参加している場合、特定の人の声だけを抽出することも苦手としています。
人間の場合、騒がしい場所(パーティー会場、繁華街など)であっても、「自分にとって関心のある話題」や「特定の人物の声」だけを選択的に聴き取ることが可能です。この効果・機能は、「カクテルパーティー効果」「選択的注意」「選択的聴取」などと呼ばれ、1953年にイギリスの心理学者コリン・チェリー(Edward Colin Cherry)よって提唱されました。
脳内での詳しいメカニズムは解明されていませんが、処理する情報量をコントロールするために、無意識のうちに、音声情報を取捨選択していると考えられています。ちなみに、聴覚だけではなく、視覚でも同様の「情報の取捨選択」が行われており、「カラーバス効果」と呼ばれています。
現時点においては、多くのAI音声認識技術では、人間の耳・脳と同レベルの精度で聴き分けることが困難です。そのため、AI音声認識を利用する際は、「雑音がない場所(静かな環境)で話す」「複数人で同時に会話しない(1人ずつ順番に話していく)」といった対策を講じましょう。ノイズを低減するソフトウェアや、高性能なマイクを使用することも重要です。
AI音声認識の活用事例

AI音声認識の主な活用事例としては、下記のようなものが挙げられます。
• 音声アシスタント
• 議事録や報告書の作成
• カルテの作成
• 外国人観光客との会話
• コールセンター業務
それぞれについて詳しく説明します。
スマートフォンに搭載されている各種音声アシスタントツールでも、AI音声認識が活用されています、以下は、その代表例です。AI音声認識の仕組みに詳しくなくても、音声アシスタント機能を利用した経験をお持ちの方は多いのではないでしょうか。
• Androidに搭載されている「Googleアシスタント」
• iPhoneに搭載されている「Siri」
Googleアシスタントでは、Google社の各種アプリ・サービスと連携し、音声だけで操作することが可能になっています。声だけで、Googleで検索できることも魅力です。
「OK、Google(グーグル)」と話しかけることで、水仕事で手が濡れている状況でも、スマートフォンに触れることなく、地図で目的地までの経路を調べたり、メールを確認したり、スケジュールを管理したりすることが可能であり、快適な生活を実現できます。
Siriでは、音声で指示を出すことで、ニュースや天気予報をチェックしたり、電話をかけたりすることが可能です。両手がふさがっている状況でも、指一本触れることなく、iPhoneを操作できます。Googleアシスタントと同様に、インターネット上で情報を検索したり、地図を見たりすることも可能です。
また、スマートスピーカー(音声で指示を出して家電製品などを操作することが可能なスピーカー)でも、AI音声認識が利用されています。Google社のGoogleアシスタントやApple社のSiriに対応した製品のほかにも、Amazon社の「Alexa」やLINE株式会社の「CLOVA」など、さまざまな企業のAI音声認識システムに対応したスマートスピーカーがリリースされています。
企業や官公庁、議会などにおいて、「会議の議事録」の作成にAI音声認識が活用されていることをご存知でしょうか。議事録を作成する担当者の労力が軽減され、労働環境が改善されるという効果に加え、リアルタイムで音声を文字に変換してモニターに表示することも可能であり、耳が不自由な方にもメリットがあります。
また、さまざまな「報告書」の作成でも、AI音声認識システムが活躍しています。例えば、駐車場(コインパーキング)の管理を行っている企業の中には、現場から「スマートフォンによる音声入力」で報告書を作成しているケースがあります。
オフィスに戻ってから報告書を手作業で作成しなくて済むため、残業する時間が減り、ワーク・ライフ・バランス(仕事と生活の両方を充実させること)の実現に役立つでしょう。
近年、医療機関において「音声でカルテを作成できるシステム」の導入が進んでいます。専門的な医療用語を学習させたAIが搭載されており、キーボードを叩かなくても文字が入力され、看護記録に加え、ほかの医療機関への紹介状も作成できることが魅力です。
医療従事者の負担軽減に役立ち、本来の業務(問診、注射などの医療行為)に、より多くの時間・労力を割くことが可能になるでしょう。また、患者側にとっても、「診察までの待ち時間が短縮される」というメリットがあります。
外国人観光客と接する機会が多い業種・業界(タクシー業界、観光地のホテル・各種レジャー施設・飲食店など)では、多言語間での翻訳が可能なアプリ(AI音声認識が搭載)を活用し、外国語での音声を日本語の文章に自動翻訳して接客を行っているケースが見受けられます。
逆に、観光客側から、アプリやポケット翻訳機を用いて外国語の音声を日本語の文章に変換してコミュニケーションを図ろうとするケースも増加中です。日常会話レベルであれば、通訳がいなくても対話が行えるので、観光客の満足度が向上するでしょう。
AI音声認識システムは、コールセンターでも活躍します。現在、AI音声認識システムが搭載されたコールセンターシステムを導入するコールセンターが増加中です。音声通話の内容がリアルタイムで自動的にテキスト化されるため、オペレーターが手入力でログを作成する必要がなくなり、業務が効率化されます。
また、単にテキスト化するだけではなく、通話内容に合わせて「FAQ」などの情報を画面上に表示できるツールもあります。
従来であれば、分厚い紙のマニュアルを利用したり、オペレーターが自らキーワードで検索するFAQシステムを利用するのが一般的で、適切な回答を見つけ出すまでオペレーターの負担が生じていました。しかし、AI音声認識システムの導入によって最適な回答スクリプト・マニュアル候補を自動表示させることが可能になることで、オペレーターの受け答えの迅速性・正確性が高まるのです。
オペレーターの応対品質が向上すれば、顧客満足度が高まります。ぜひ、AI音声認識機能が搭載されたコールセンターシステムの導入をご検討ください。
>>リアルタイム音声認識でモニタリング体制を構築!応対品質を向上した事例はこちら
• 音声アシスタント
• 議事録や報告書の作成
• カルテの作成
• 外国人観光客との会話
• コールセンター業務
それぞれについて詳しく説明します。
音声アシスタント
スマートフォンに搭載されている各種音声アシスタントツールでも、AI音声認識が活用されています、以下は、その代表例です。AI音声認識の仕組みに詳しくなくても、音声アシスタント機能を利用した経験をお持ちの方は多いのではないでしょうか。
• Androidに搭載されている「Googleアシスタント」
• iPhoneに搭載されている「Siri」
Googleアシスタントでは、Google社の各種アプリ・サービスと連携し、音声だけで操作することが可能になっています。声だけで、Googleで検索できることも魅力です。
「OK、Google(グーグル)」と話しかけることで、水仕事で手が濡れている状況でも、スマートフォンに触れることなく、地図で目的地までの経路を調べたり、メールを確認したり、スケジュールを管理したりすることが可能であり、快適な生活を実現できます。
Siriでは、音声で指示を出すことで、ニュースや天気予報をチェックしたり、電話をかけたりすることが可能です。両手がふさがっている状況でも、指一本触れることなく、iPhoneを操作できます。Googleアシスタントと同様に、インターネット上で情報を検索したり、地図を見たりすることも可能です。
また、スマートスピーカー(音声で指示を出して家電製品などを操作することが可能なスピーカー)でも、AI音声認識が利用されています。Google社のGoogleアシスタントやApple社のSiriに対応した製品のほかにも、Amazon社の「Alexa」やLINE株式会社の「CLOVA」など、さまざまな企業のAI音声認識システムに対応したスマートスピーカーがリリースされています。
議事録や報告書の作成
企業や官公庁、議会などにおいて、「会議の議事録」の作成にAI音声認識が活用されていることをご存知でしょうか。議事録を作成する担当者の労力が軽減され、労働環境が改善されるという効果に加え、リアルタイムで音声を文字に変換してモニターに表示することも可能であり、耳が不自由な方にもメリットがあります。
また、さまざまな「報告書」の作成でも、AI音声認識システムが活躍しています。例えば、駐車場(コインパーキング)の管理を行っている企業の中には、現場から「スマートフォンによる音声入力」で報告書を作成しているケースがあります。
オフィスに戻ってから報告書を手作業で作成しなくて済むため、残業する時間が減り、ワーク・ライフ・バランス(仕事と生活の両方を充実させること)の実現に役立つでしょう。
カルテの作成
近年、医療機関において「音声でカルテを作成できるシステム」の導入が進んでいます。専門的な医療用語を学習させたAIが搭載されており、キーボードを叩かなくても文字が入力され、看護記録に加え、ほかの医療機関への紹介状も作成できることが魅力です。
医療従事者の負担軽減に役立ち、本来の業務(問診、注射などの医療行為)に、より多くの時間・労力を割くことが可能になるでしょう。また、患者側にとっても、「診察までの待ち時間が短縮される」というメリットがあります。
外国人観光客との会話
外国人観光客と接する機会が多い業種・業界(タクシー業界、観光地のホテル・各種レジャー施設・飲食店など)では、多言語間での翻訳が可能なアプリ(AI音声認識が搭載)を活用し、外国語での音声を日本語の文章に自動翻訳して接客を行っているケースが見受けられます。
逆に、観光客側から、アプリやポケット翻訳機を用いて外国語の音声を日本語の文章に変換してコミュニケーションを図ろうとするケースも増加中です。日常会話レベルであれば、通訳がいなくても対話が行えるので、観光客の満足度が向上するでしょう。
コールセンター業務
AI音声認識システムは、コールセンターでも活躍します。現在、AI音声認識システムが搭載されたコールセンターシステムを導入するコールセンターが増加中です。音声通話の内容がリアルタイムで自動的にテキスト化されるため、オペレーターが手入力でログを作成する必要がなくなり、業務が効率化されます。
また、単にテキスト化するだけではなく、通話内容に合わせて「FAQ」などの情報を画面上に表示できるツールもあります。
従来であれば、分厚い紙のマニュアルを利用したり、オペレーターが自らキーワードで検索するFAQシステムを利用するのが一般的で、適切な回答を見つけ出すまでオペレーターの負担が生じていました。しかし、AI音声認識システムの導入によって最適な回答スクリプト・マニュアル候補を自動表示させることが可能になることで、オペレーターの受け答えの迅速性・正確性が高まるのです。
オペレーターの応対品質が向上すれば、顧客満足度が高まります。ぜひ、AI音声認識機能が搭載されたコールセンターシステムの導入をご検討ください。
>>リアルタイム音声認識でモニタリング体制を構築!応対品質を向上した事例はこちら
コールセンター業務でAI音声認識を活用するなら、オムニアリンクがおすすめ
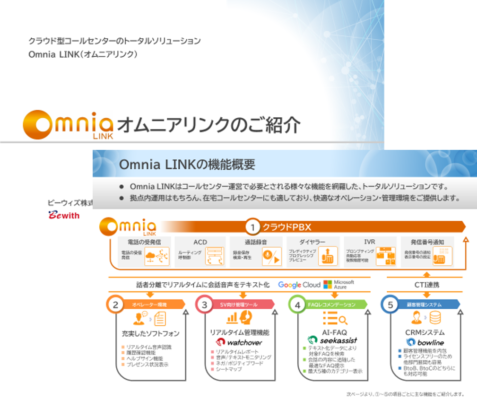
ビーウィズのコールセンターシステム(クラウドPBX)「オムニアリンク(Omnia LINK)」には、高精度な音声認識システムが標準搭載されています(Google Cloud Platformの Cloud Speech APIを採用)。オムニアリンクでは、音声通話の内容がリアルタイムで全てテキスト化されるので、オペレーターが自分でメモを取る必要がありません。
音声データのままでは、SVが同時に複数のオペレーターの通話内容を把握できませんが、テキストデータの形になるので、SV用の管理画面(watchover)から、複数のオペレーターを同時にモニタリングすることが可能になります。
使いやすさにこだわったコールセンター専用のAI-FAQツール「seekassist(シークアシスト)」も、ぜひご活用ください。AIが対話内容に合わせて最適なFAQ候補を自動表示するので、検索する手間が省けます。FAQに加えて、「商品情報」「店舗住所」「キャンペーン内容」「クロスセル商品」も同時に表示されるため、新人オペレーターでも、顧客からの質問にスムーズに対応できるでしょう。
また、苦情や解約につながる「ネガティブワード」や、契約につながる「ポジティブワード」を登録しておくことで、通話中に登録ワードが発せられたタイミングで警告を出す「キーワードアラート機能」も魅力です。SVが迅速にオペレーターをフォローするのに役立ちます。
さらに、VPN接続により、在宅でコールセンターを遂行する環境を安全かつ簡単に構築できるので、在宅勤務の推進を検討しているコールセンターにも最適です。ワーク・ライフ・バランスの改善によるオペレーター定着率向上(離職率低下)や、BCP対策などに寄与します。もちろん、新たに人材を雇い入れることも容易になり、人手不足の解消につながります。
コールセンターは、顧客の生の声(VoC、Voice of Customer)が集積する場です。音声のままでは分析が困難ですが、オムニアリンクならテキストデータの形で保存されるため、テキストマイニングツールなどによって分析することで、マーケティングや商品・サービスの開発に活かすことが可能になり、顧客満足度の向上を実現できるでしょう。
オムニアリンクが優れている点は、AI音声認識機能だけではありません。外部のCRMツールとCTI連携して、顧客情報(氏名、住所、年齢、性別など)や、オペレーターの応対履歴を画面上に自動表示できることもメリットです。以下に、これまでに連携した実績のある外部CRMツールを示します(カッコ内は、ツールを開発・販売している業者名)。
• Salesforce(セールスフォース・ドットコム社)
• kintone(サイボウズ社)
• zendesk(Zendesk社)
• T-SQUAREx(東芝デジタルソリューションズ社)
• inspirX(バーチャレクス・コンサルティング社)
上記CRMツールであれば、大きな手間をかけることなく、スムーズに連携できるでしょう。「特にCRMツールを使用していない」という場合は、オムニアリンク専用の標準CRMツール「アレンジデスク」、または、オプションでお選びいただけるインバウンド向けCRMツール「ボウライン」を利用することもご検討ください。
初期費用は「300,000円~」、月額料金は「基本料金が100,000円~、Omnia LINK使用料が1席あたり9,000円」です。ライセンス数は1ヶ月単位で増減できるので、業務の繁閑に合わせてご調整ください。オプション機能に関しては、別途、費用が発生します。
導入時にトレーニングを実施することも可能です。ご用件をお聞きして、別途、お見積りいたします。まずは、資料をダウンロードして閲覧したうえで、不明な点がある場合は、電話(0120-722-782、受付時間:平日9時30分~18時30分)または問い合わせフォームにて、お気軽にご質問・ご相談ください。
音声データのままでは、SVが同時に複数のオペレーターの通話内容を把握できませんが、テキストデータの形になるので、SV用の管理画面(watchover)から、複数のオペレーターを同時にモニタリングすることが可能になります。
使いやすさにこだわったコールセンター専用のAI-FAQツール「seekassist(シークアシスト)」も、ぜひご活用ください。AIが対話内容に合わせて最適なFAQ候補を自動表示するので、検索する手間が省けます。FAQに加えて、「商品情報」「店舗住所」「キャンペーン内容」「クロスセル商品」も同時に表示されるため、新人オペレーターでも、顧客からの質問にスムーズに対応できるでしょう。
また、苦情や解約につながる「ネガティブワード」や、契約につながる「ポジティブワード」を登録しておくことで、通話中に登録ワードが発せられたタイミングで警告を出す「キーワードアラート機能」も魅力です。SVが迅速にオペレーターをフォローするのに役立ちます。
さらに、VPN接続により、在宅でコールセンターを遂行する環境を安全かつ簡単に構築できるので、在宅勤務の推進を検討しているコールセンターにも最適です。ワーク・ライフ・バランスの改善によるオペレーター定着率向上(離職率低下)や、BCP対策などに寄与します。もちろん、新たに人材を雇い入れることも容易になり、人手不足の解消につながります。
コールセンターは、顧客の生の声(VoC、Voice of Customer)が集積する場です。音声のままでは分析が困難ですが、オムニアリンクならテキストデータの形で保存されるため、テキストマイニングツールなどによって分析することで、マーケティングや商品・サービスの開発に活かすことが可能になり、顧客満足度の向上を実現できるでしょう。
オムニアリンクが優れている点は、AI音声認識機能だけではありません。外部のCRMツールとCTI連携して、顧客情報(氏名、住所、年齢、性別など)や、オペレーターの応対履歴を画面上に自動表示できることもメリットです。以下に、これまでに連携した実績のある外部CRMツールを示します(カッコ内は、ツールを開発・販売している業者名)。
• Salesforce(セールスフォース・ドットコム社)
• kintone(サイボウズ社)
• zendesk(Zendesk社)
• T-SQUAREx(東芝デジタルソリューションズ社)
• inspirX(バーチャレクス・コンサルティング社)
上記CRMツールであれば、大きな手間をかけることなく、スムーズに連携できるでしょう。「特にCRMツールを使用していない」という場合は、オムニアリンク専用の標準CRMツール「アレンジデスク」、または、オプションでお選びいただけるインバウンド向けCRMツール「ボウライン」を利用することもご検討ください。
初期費用は「300,000円~」、月額料金は「基本料金が100,000円~、Omnia LINK使用料が1席あたり9,000円」です。ライセンス数は1ヶ月単位で増減できるので、業務の繁閑に合わせてご調整ください。オプション機能に関しては、別途、費用が発生します。
導入時にトレーニングを実施することも可能です。ご用件をお聞きして、別途、お見積りいたします。まずは、資料をダウンロードして閲覧したうえで、不明な点がある場合は、電話(0120-722-782、受付時間:平日9時30分~18時30分)または問い合わせフォームにて、お気軽にご質問・ご相談ください。
関連コラム(今さら聞けない!? 初歩の初歩)
- 「クラウド型PBX」とは?仕組みについて解説し、おすすめのサービスもご紹介!
- これからのコールセンターでは音声認識システムが必須!通話内容をテキスト化して、サービス改善や商品開発に活かそう
- 「PBX」とは?種類や機能など、導入する前に知っておきたいことについて徹底解説!
- コールセンターシステムとは?機能解説と選び方・メリットをまとめました
- 「ソフトフォン」とは?パソコンとインターネット接続環境があれば通話が可能に!
- クラウドPBXのメリットをご紹介!デメリットや注意点についても解説
- コールセンターを開設・運営するなら、「クラウドPBX」を選択しよう!メリットについて徹底解説
- これからのコールセンターにはAIの導入が不可欠!メリットや上手な活用方法をご紹介
- クラウドPBXのデメリットとは?導入する際に注意すべき点をご紹介!
- 個人/小規模事業者にはクラウドPBXがおすすめ!導入すべき理由を徹底解説
- コールセンターの運営に欠かせない「CRM」とは?選定する際のポイントを徹底解説!
- クラウドPBXの導入・運用コストは、どのくらい?初期費用や月額料金の相場をご紹介!
- コールセンター運営のポイントを徹底解説!人材の育成方法もご紹介
- PBX(電話交換機)を導入すると、何ができる?代表的な機能をご紹介!
- 「ビジネスフォン」とは?一般的な電話機との違いについて徹底解説!
- 「IVR」とは?活用されるシーンや導入するメリットをご紹介!
- 「オンプレミス型」とは?「クラウド型」との違いについて徹底解説!
- 「内線電話」とは?仕組みや、機能・使い方、メリット、導入する際に注意すべき点を詳しく解説!
- 「CTI」とは?役割やメリット、選び方などについて徹底解説!
- 在宅コールセンターとは?メリットや注意点、導入方法について詳しく解説
- クラウド電話とは?メリットや注意すべき点、どのような企業が導入するべきなのかをご紹介!
- 監視カメラの設置は必要?在宅コールセンターでの従業員の管理方法をご紹介!
- AI音声認識の仕組みを徹底解説!メリットや課題、活用事例もご紹介
- コールセンターの運用に欠かせないACDとは?機能やメリットについて詳しく解説!
- CRMシステムとは?機能や活用するメリットについて詳しく解説!
- コールセンターの生産性管理に役立つ指標とは?さまざまな工夫をして改善に努めよう!

